Доброчанька
12/05/2022 (Mon) 01:27
No.986
del
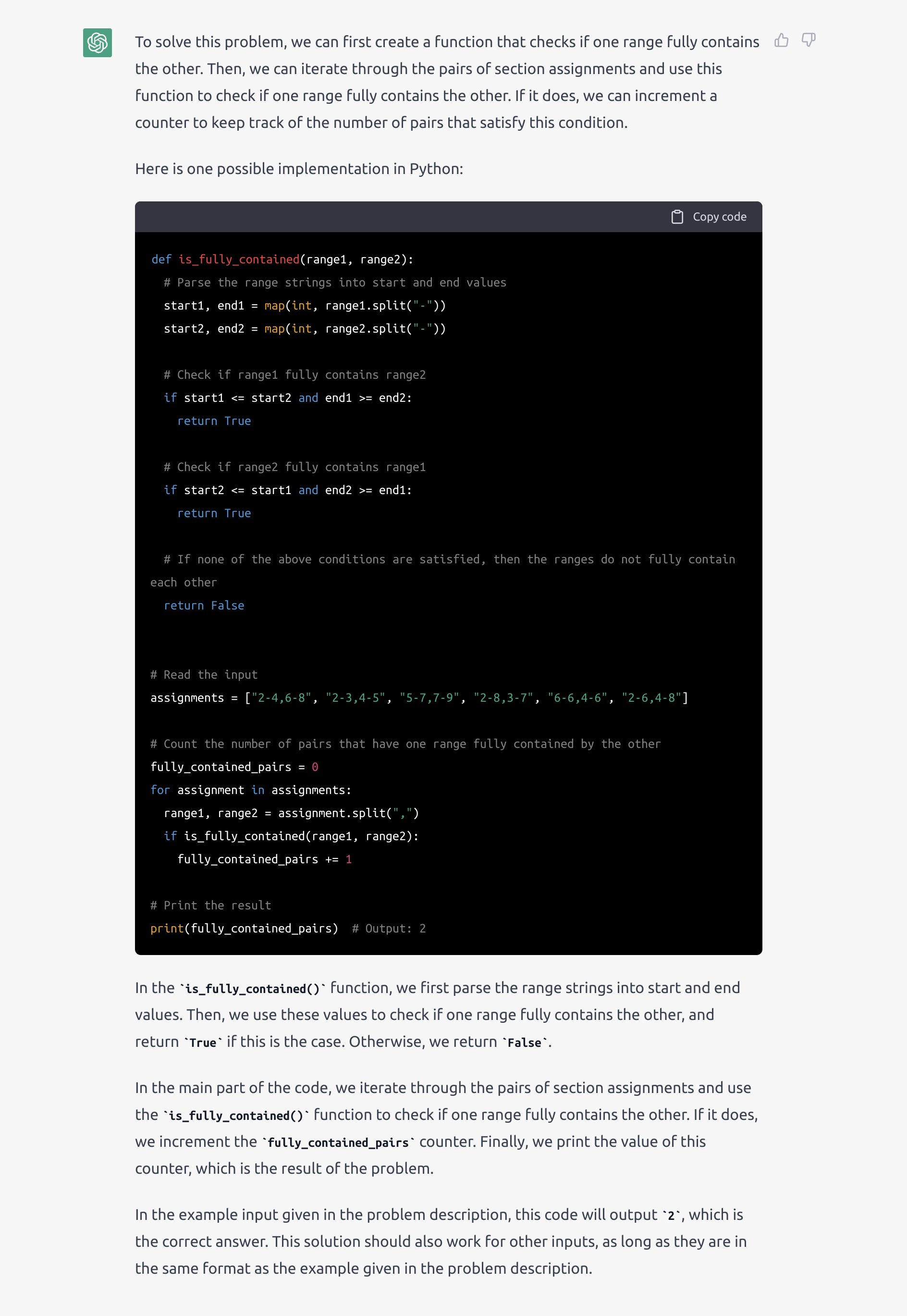
https://beta.character.ai – все уже видели, я полагаю.
Мультимодальному диалогу будут учить на чём-то подобном (вернее, OpenAI уже наверняка научили и скоро вынесут весь рынок с GPT-4)
[MMDialog is a dataset to better facilitate multi-modal conversation](https://flight.beehiiv.net/v2/clicks/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJodHRwczovL2FyeGl2Lm9yZy9hYnMvMjIxMS4wNTcxOSIsInBvc3RfaWQiOiI0YzVlMmNmZS0xNjM3LTQ1MTAtYTBlNC1mZWE3N2FhZTUyNDEiLCJwdWJsaWNhdGlvbl9pZCI6IjQ0N2Y2ZTYwLWUzNmEtNDY0Mi1iNmY4LTQ2YmViMTkwNDVlYyIsInZpc2l0X3Rva2VuIjoiNzE0NjkwNDAtZmNlYy00ODZjLWEyNTUtOWE0ZTFiYzA2NjkxIiwiaWF0IjoxNjY4NTY3MjgyLjUzOCwiaXNzIjoib3JjaGlkIn0.Z36hzCB1ZaJWSDsIe8z2EALeSeAs5RvB5dFSeATPgXs). Its composed of a curated set of 1.08 million real-world dialogues with 1.53 million unique images across 4,184 topics.
https://dataconomy.com/2022/10/deepmind-sparrow-safer-precise-revealed/ – очередная кастрированная "безопасная" диалоговая модель от гугла.
ChatGPT… все уже видели. Это слабый AGI, в общем-то. Даже не очень слабый – IQ так 80-90. Хорошо говорит, хорошо рифмует, хорошо программирует, может признавать ошибки и исправляться. Без человеческого надзора не справится. Пока что. Месяц-другой.
https://twitter.com/davidtsong/status/1598767389390573569
https://mobile.twitter.com/SergeyI49013776/status/1598430479878856737
https://twitter.com/GuiAmbros/status/1599282083838296064
https://gist.github.com/Gaelan/cf5ae4a1e9d8d64cb0b732cf3a38e04a
https://arxiv.org/abs/2212.00616 – расширение идеи текстовой инверсии в image generation на текст, использование псевдослов, которые компактно описывают некоторое подмножество датасета (например, стиль речи).
И опять зрелые бенчмарки.
We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time).
https://arxiv.org/abs/2211.09110
Мультимодальному диалогу будут учить на чём-то подобном (вернее, OpenAI уже наверняка научили и скоро вынесут весь рынок с GPT-4)
[MMDialog is a dataset to better facilitate multi-modal conversation](https://flight.beehiiv.net/v2/clicks/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJodHRwczovL2FyeGl2Lm9yZy9hYnMvMjIxMS4wNTcxOSIsInBvc3RfaWQiOiI0YzVlMmNmZS0xNjM3LTQ1MTAtYTBlNC1mZWE3N2FhZTUyNDEiLCJwdWJsaWNhdGlvbl9pZCI6IjQ0N2Y2ZTYwLWUzNmEtNDY0Mi1iNmY4LTQ2YmViMTkwNDVlYyIsInZpc2l0X3Rva2VuIjoiNzE0NjkwNDAtZmNlYy00ODZjLWEyNTUtOWE0ZTFiYzA2NjkxIiwiaWF0IjoxNjY4NTY3MjgyLjUzOCwiaXNzIjoib3JjaGlkIn0.Z36hzCB1ZaJWSDsIe8z2EALeSeAs5RvB5dFSeATPgXs). Its composed of a curated set of 1.08 million real-world dialogues with 1.53 million unique images across 4,184 topics.
https://dataconomy.com/2022/10/deepmind-sparrow-safer-precise-revealed/ – очередная кастрированная "безопасная" диалоговая модель от гугла.
ChatGPT… все уже видели. Это слабый AGI, в общем-то. Даже не очень слабый – IQ так 80-90. Хорошо говорит, хорошо рифмует, хорошо программирует, может признавать ошибки и исправляться. Без человеческого надзора не справится. Пока что. Месяц-другой.
https://twitter.com/davidtsong/status/1598767389390573569
https://mobile.twitter.com/SergeyI49013776/status/1598430479878856737
https://twitter.com/GuiAmbros/status/1599282083838296064
https://gist.github.com/Gaelan/cf5ae4a1e9d8d64cb0b732cf3a38e04a
https://arxiv.org/abs/2212.00616 – расширение идеи текстовой инверсии в image generation на текст, использование псевдослов, которые компактно описывают некоторое подмножество датасета (например, стиль речи).
И опять зрелые бенчмарки.
We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time).
https://arxiv.org/abs/2211.09110
Message too long. Click here to view full text.